
Sep 25, 2024
Unleashing the power of Intel platforms in federated learning
For the complete whitepaper please click HERE
ASUS is an OEM passionate about technology and driven by innovation as well as able to provide from various computer portfolio to AI and data center solutions. In addition to its profound expertise in hardware design, ASUS continues to develop high performance computing, cloud service software architectures to enable overall solutions.
With its expertise in AI applications, ASUS has worked with Intel to realize Federated Learning training by using 4th Gen Intel® Xeon® Scalable processor. In this paper, ASUS presents a comprehensive AI solution based on Federated Learning training models and Intel's exclusive AI optimization methods. The purpose of this study is to demonstrate ASUS' integration with CPU computing power and AI technologies. A meticulous investigation has been conducted by ASUS into the experimental design and methodology used to assess the performance of Intel CPUs within the dynamic landscape of Federated Learning (FL). Intel® Xeon® Scalable processors are designed to accelerate performance across a wide range of workloads, including artificial intelligence (AI), data analytics, networking, storage, and high-performance computing. In this field study, ASUS worked with Imaging Lab, National Taipei University of Nursing and Health Sciences, which is the professional research team focusing in smart medical and AI workloads. Dataset processing, AI Model formation, are handled by Shen, Bo-An and Zhan, Yu-Xun.
Challenges in Federated Learning
Federated Learning initiatives are pivotal in propelling the field of medical AI forward. They achieve this by offering funding, setting standards, regulating practices, encouraging collaboration, and supporting education and workforce development. Through the utilization of these initiatives, stakeholders within the healthcare ecosystem can tap into the transformative capabilities of AI, thereby enhancing patient outcomes, refining clinical decision-making processes, and spurring innovation in medical research and practice.
However, addressing critical issues such as AI architectures, data management, and accuracy across multiple locations remains paramount. Optimizing algorithms, hardware platforms, and methodologies are pivotal factors that can amplify the efficacy of Federated Learning implementations in medical segments. It is imperative to strategize and invest in solutions that streamline these technical aspects, ensuring seamless integration and robust performance of AI-driven systems across diverse healthcare settings. By prioritizing these considerations, Federated Learning initiatives can further bolster their impact and facilitate the broader adoption of AI technologies in healthcare.
How to Enable a Comprehensive AI Platform?
To speed up Federated Learning adoption in the smart medical industry, the ASUS data center solution team is trying to adopt the latest Intel® Xeon® Scalable processors to optimize Federated Learning performance with Intel built-in AI software toolkits and solutions. With this cutting-edge technology, 5th Gen Intel® Xeon® Scalable Processors delivers better performance to improve overall AI efficiency and accuracy.
Our Experiment
We tested under settings in the Federated Learning framework(Flower, https://github.com/adap/flower), with Intel solution, from accuracy, loss comparison, and time comparison, which showed the latest Intel solution is the optimized solution to Federated Learning AI.
In this experiment, we aim to investigate the efficacy of leveraging Intel's suite of optimization tools, including oneDNN, Intel Distribution for Python, and Intel Extension for PyTorch, in the context of Federated Learning through Intel® VTune Profiler, a performance profiling tool used to investigate performance issues and learn the performance insights. By conducting controlled experiments using our select AlexNet and VGG19 models, which are commonly evaluated for medical image recognition applications, and the fundamental models for deriving our own research model on the particular medical application, we seek to evaluate the impact of integrating Intel's tools into FL client environments. Our research model's parameter size was estimated to be between those of the AlexNet and VGG19 models. Specifically, our experimental setup includes a control group with standard Python environments and an experimental group where Intel tools are incorporated, allowing for a comparative analysis of training efficiency, convergence rates, and model accuracy. This investigation aims to provide valuable insights into the potential benefits of utilizing Intel's optimization solutions for Federated Learning scenarios. The experiment code and steps are in this Github repository we provide.
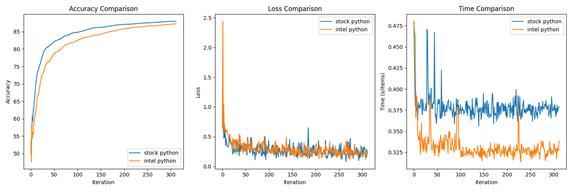
- AlexNet
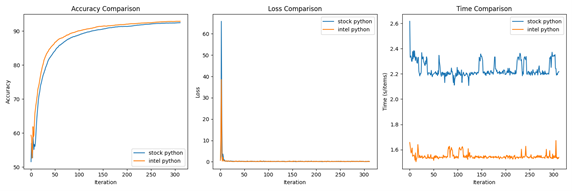
- VGG19
- Intel® VTune™ Profiler results comparison.
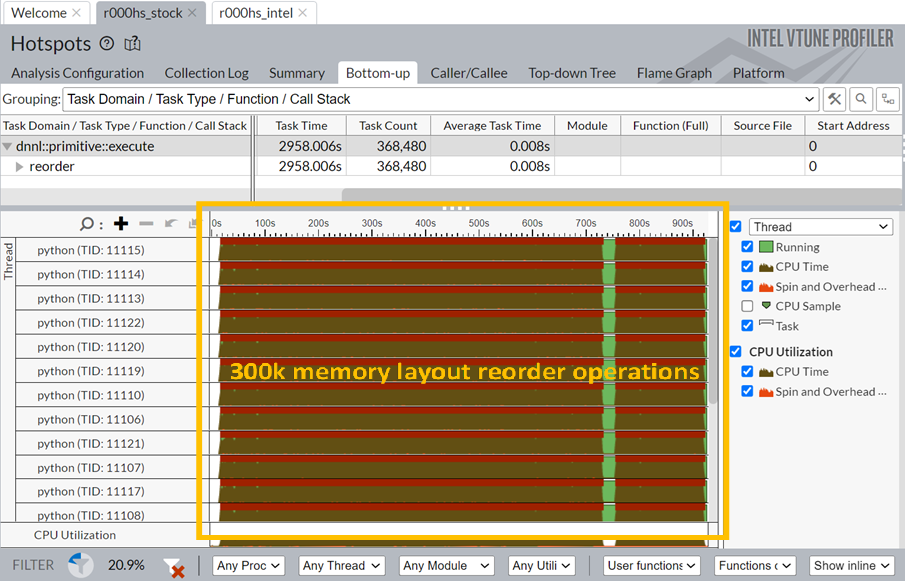
VTune Figure 1, oneDNN reorder CPU time consumtion(unoptimized)
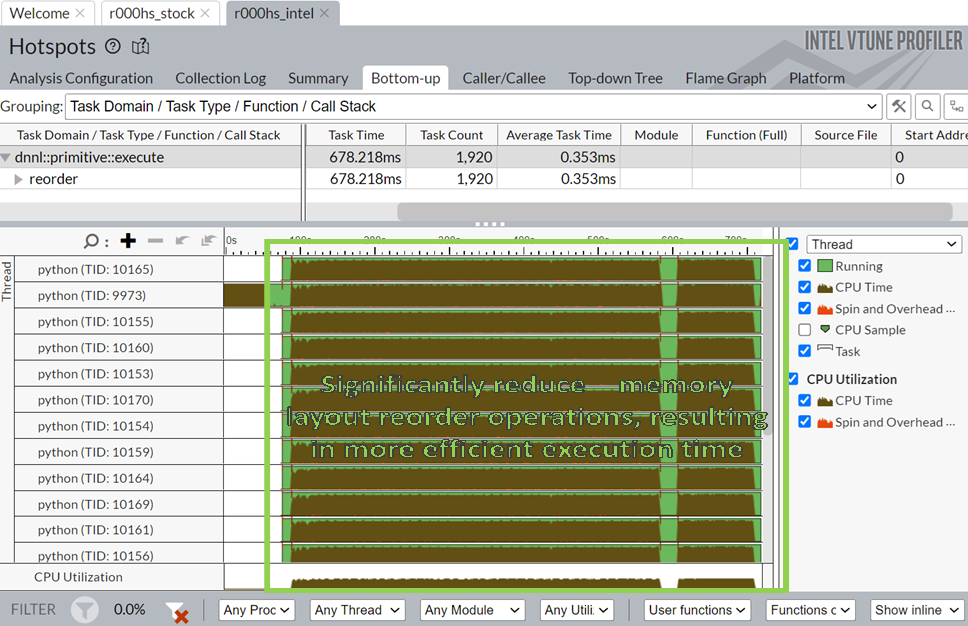
VTune Figure 2, oneDNN reorder CPU time consumption (Intel optimization)
Performance (Results & Benefits)
Based on the results of our experiment, it is evident that integrating Intel's optimization tools, including oneDNN, Intel Distribution for Python, and Intel Extension for PyTorch, into federated learning environments can yield substantial improvements in efficiency, particularly for more complex models like VGG19. Our findings reveal an average efficiency improvement of 13% for AlexNet and an impressive 30% for VGG19, indicating that the complexity of the model plays a significant role in the extent of enhancement achievable. Moreover, detailed analysis using Intel VTune uncovered that the primary driver behind the efficiency gains in VGG19 is the reduction of oneDNN’s reordering operations, resulting in a remarkable reduction in CPU time from 2958s to 0.6s. While these advancements are promising, it is important to note a crucial limitation: the necessity for all clients in federated learning to adopt Intel Extension for PyTorch if any one client chooses to use it. This requirement introduces potential compatibility constraints and operational complexities within federated learning setups. In conclusion, while our experiment showcases the considerable benefits of leveraging Intel's optimization tools for federated learning, further exploration is warranted to address the associated challenges and maximize the scalability and usability of such solutions in distributed machine learning environments.
We have achieved impressive efficiency gains by collaborating with Intel and National Taipei University of Nursing and Health Sciences (NTUNHS) on implementing Federal Learning medical image recognition in ASUS's server products with Intel 4th Gen Xeon Scale Processors. Integrating Intel oneAPI software tools and Intel Extension for PyTorch into Federated Learning environments has resulted in a 13% increase in efficiency for AlexNet and a 30% increase for VGG19 in medical image recognition applications. With the help of Intel oneAPI's VTune, we found that OneDNN's operation reordering significantly reduced CPU computation time for deep learning model training. Intel Software optimization tools deliver values by enhancing performance in distributed machine learning environments without compromising data privacy." - Paul Ju, Corp VP, CTO & Infrastructure Solution Group GM, ASUS
Federated Learning Test Result - Training Accuracy
The comparison of train accuracy, which tracks the cumulative number of correct predictions during training, between two configurations of Python— the stock community version and the Intel optimization version (Intel Distribution for Python and Intel Extension for Pytorch) — in the context of Federated Learning tasks. It shows how well the model is learning from data Despite introducing randomness in dataset preprocessing, both configurations exhibit similar stability across different training rounds, ultimately resulting in a converged model.
Federated Learning Test Result - Train Loss
In the domain of loss measurement, the stock version of Python showcases marginally reduced values in comparison to the Intel optimization version, which registers a slight uptick of approximately 0.1 percentage points. This discrepancy, although seemingly minor, holds significant implications for the optimization of Federated Learning (FL) scenarios. The observation underscores the critical importance of honing Intel's optimization strategies to ensure optimal performance in FL environments. Given the intricate nature of FL tasks, even subtle deviations in loss metrics can signify underlying nuances in algorithmic execution and model convergence. Consequently, Intel's optimization methodologies become imperative for achieving precision and efficiency in FL operations. By addressing these nuanced discrepancies and continually refining optimization strategies, we can bolster the Federated Learning framework’s capacity to meet the evolving demands of FL applications, thereby advancing the landscape of distributed machine learning paradigms.
Federated Learning Test Result – Training Time
In terms of time efficiency, a standout discovery emerges regarding the computational performance of the two configurations. The Intel optimization Python development environment notably surpasses the stock version Python environment concerning processing time, boasting a nearly 30% performance advantage in the average iteration training time in this test. This considerable decrease in processing time underscores the tangible advantages of harnessing Intel's CPU optimizations, particularly in Federated Learning (FL) environments where efficiency holds paramount importance.
Competitive Advantage
In summary, while the stock version of Python may demonstrate a marginal advantage in accuracy and loss metrics, the Intel Distribution for Python presents a compelling superiority in computational efficiency, evidenced by markedly faster processing times. These discoveries underscore the potential of Intel's CPU optimization techniques to augment the performance of Federated Learning (FL) frameworks, especially in demanding healthcare applications where real-time processing and efficiency are imperative.
Nevertheless, continued optimization efforts are needed to narrow the accuracy gap observed between the two configurations. By addressing this disparity, Intel can further solidify its position as a leading provider of optimized computing solutions for FL applications, facilitating the advancement of healthcare analytics and patient-centric care delivery. Through collaborative endeavors and ongoing innovation, stakeholders can harness the full potential of Intel's technology advancements to propel the evolution of FL frameworks, ultimately enhancing the quality and efficiency of healthcare services on a global scale.
Conclusion
In conclusion, our experiment has shed light on the remarkable potential of integrating Intel's optimization tools into federated learning environments, unlocking significant improvements in efficiency for complex models like VGG19. With an average efficiency gain of 13% for AlexNet and a staggering 30% for VGG19, our findings demonstrate the transformative power of Intel's optimization tools in accelerating the performance of federated learning. As we delve deeper into the intricacies of our results, it's clear that the reduction of oneDNN’s reordering operations holds the key to these remarkable gains, slashing CPU time from a staggering 2958s to a mere 0.6s. While these advancements are undeniably promising, we must acknowledge the crucial limitation that requires all clients to adopt Intel Extension for PyTorch to reap the benefits. As we continue to push the boundaries of federated learning, we're excited to explore the vast possibilities that these optimizations hold, and we invite you to join us on this journey of innovation by learning more about Federated AI.
Please stay tuned an upcoming thorough assessment of ASUS's Intel® Data Center GPU Flex Series server is set to reveal more impressive outcomes, demonstrating the server's effectiveness in assisting actual medical disease cases.
For the complete whitepaper, please click HERE
Access to the supplementary material: https://github.com/cylab-tw

