
Mar 4, 2025
Designing AI Clusters: Network Infrastructure for Efficient Data Center Operations
The rapid advancement of artificial intelligence (AI) over the past decade has led to a significant increase in demand for powerful GPU clusters. These clusters are essential for supporting various AI workloads, including training, inference, high-performance computing (HPC), and generative AI applications. The design of these clusters varies in size and configuration, to meet specific workload demands. This article explores the network infrastructure requirements necessary for efficient data center operations.
Key Components of AI Clusters
An AI cluster typically consists of the following components:
- GPU node: The primary compute element responsible for executing AI workloads.
- Shared node: Connects shared resources such as storage and other essential services.
- Management node: Handles cluster management, monitoring, and orchestration tasks.
- Networking switch: Facilitates connectivity and communication between nodes.
Network Infrastructure Requirements
AI workloads are highly compute-intensive and require robust network infrastructure to ensure optimal performance. A cluster networking fabric typically includes a front-end (N/S) fabric, a back-end (E/W) fabric, and an out-of-band (OOB) fabric. When building a network, key considerations include:
- Maximum throughput: AI applications demand high-speed data transfer rates to support their computational intensity.
- Minimal latency: Reducing latency is crucial as it significantly impacts the time required for training large AI models.
- Scalability: The ability to scale up or out according to workload demands is vital. This involves using scalable networking solutions that can handle increased GPU density without compromising performance.
Design Approach
Designing an AI cluster involves integration of dedicated networking fabrics across different traffic flows.
North-south (N/S) network
The north-south or front-end network connects the AI cluster to external networks, users, and data storage systems. It facilitates storage, management, and other in-band communications. In the context of the HGX H200 topology, NVIDIA Spectrum-4™ SN5000 series are deployed for both in-band and storage fabric, ensuring efficient and high-performance connectivity.
- Storage network: Enables the seamless transfer of large datasets required for AI training and inference.
- Management network: Ensures smooth operation and orchestration of AI workloads by handling management traffic.
East-west (E/W) network
- The east-west or back-end network is crucial for AI clusters as it supports high-bandwidth, low-latency communication between GPU nodes. This network fabric is dedicated to GPU compute tasks, ensuring optimal performance for AI workloads. For the HGX H200 topology, the NVIDIA Spectrum-4 SN5000 series is also utilized for Ethernet protocol communication, providing the necessary bandwidth and low latency.
- GPU Compute Fabric: Facilitates efficient inter-node GPU communication, essential for parallel processing and distributed AI training.
Out-of-band (OOB) network
- Out-of-Band (OOB) management LAN is designed to provide a dedicated communication channel for remote device management. This network operates independently of the primary network, allowing IT administrators to manage, monitor, and perform critical tasks without interfering with the main data traffic. In the HGX H200 topology, the NVIDIA Spectrum SN2000 Series switch is used for OOB management.
- Management LAN: Also known as lights-out management (LOM), this network ensures that administrators can perform remote management tasks securely and efficiently.
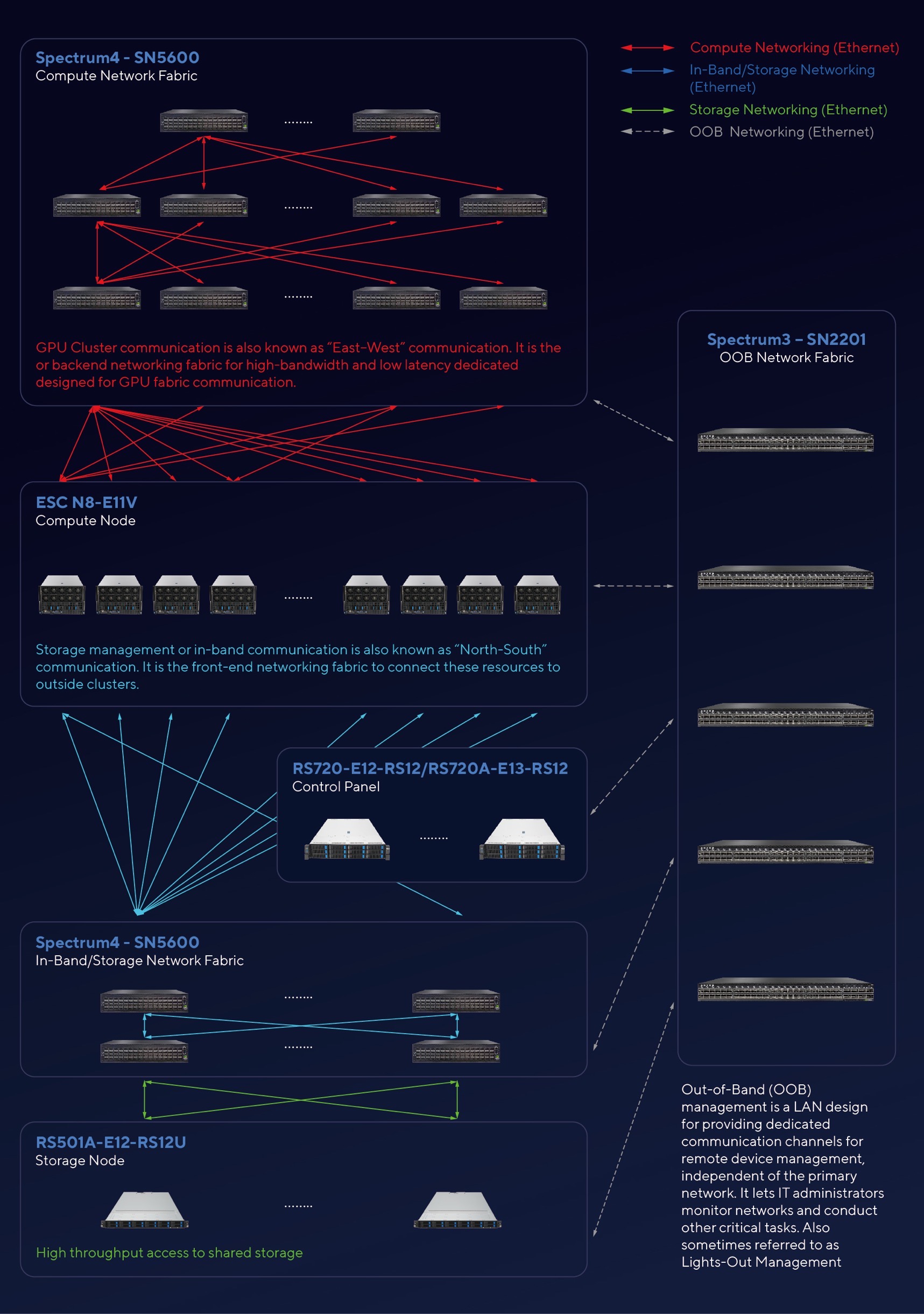
Technologies Supporting Scalable Networking Solutions
To stay competitive in the evolving AI landscape, data centers must adopt technologies such as:
- High-speed switches: Devices like NVIDIA Spectrum-4 SN5600 and NVIDIA Spectrum SN2000 series provide advanced features necessary for handling high-bandwidth requirements while minimizing latency.
- Kubernetes orchestration: Utilizing Kubernetes helps manage complex HPC environments by optimizing resource allocation across multiple GPUs.
Conclusion
As AI advancements continue, there will be an increasing need for sophisticated networking solutions capable of supporting massive computational demands efficiently. By integrating scalable networking fabrics with advanced technologies like high-speed switches and orchestration tools, data centers can ensure they remain at the forefront of this technological evolution.

