-
超乎想像的 AI。 盡情釋放。
在華碩的支持下,將您的 NVIDIA GB200 概念化為現實
透過由 NVIDIA GB200 Grace™ Blackwell Superchips 驅動的華碩 AI POD,釋放您 AI 基礎架構的完整潛力。這個增強型的 AI 系統旨在加速即時萬億參數模型,例如 LLM 和 MoE,為大型 AI 專案、超大規模資料中心和研究計畫提供無與倫比的效能。 華碩 AI POD 專為推動創新的企業和研發團隊量身打造,讓您能夠突破可能的界限,同時透過華碩獨有的軟體驅動方法加速上市時間。

-

Blackwell 架構 GPU
採用 TSMC 4NP 製程的 2080 億個電晶體
-

第二代 Transformer Engine
透過 FP4 啟用,效能提升一倍
-

第五代 NVLink & NVLink Switch
1.8 TB/s GPU-GPU 互連
-
-
NVIDIA Blackwell GPU 突破
華碩 AI POD 包含 NVIDIA GB200 Grace™ Blackwell Superchips,每個晶片封裝 2080 億個電晶體。NVIDIA Blackwell GPU 具有兩個光罩尺寸限制的晶粒,透過每秒 10 TB (TB/s) 的晶片對晶片互連連接在統一的單個 GPU 中。NVIDIA GB200 NVL72 在 FP4 精度下提供 1,440 PFLOPS 的運算能力,利用其先進的 Tensor Cores 和第五代 NVLink 互連來實現 AI 工作負載的高效能。
-
-

 1 1 2 3 4 5 5 6 6 7 8 9 10
1 1 2 3 4 5 5 6 6 7 8 9 101NVIDIA BlueField®-3 DPUs (B3240)
2PDB
3內部歧管
4風扇區域
5NVIDIA ConnectX®-7 夾層網路卡
6NVIDIA GB200 Grace™ Blackwell Superchips
7HMC 模組
8液體冷卻出口
9匯流排夾
10液體冷卻入口
-

 1 2 2 3 4 5 6 7 8 9 9
1 2 2 3 4 5 6 7 8 9 91NVIDIA BlueField®-3 DPUs (B3240)
22 x OSFP 400G
31G PXE
48* E1.S
5BMC
6USB 3.2
7miniDP
8NVIDIA BlueField®-3 DPUs (B3240)
92 x OSFP 400G
-

 1 2 2 3 4 4 5
1 2 2 3 4 4 51液體冷卻出口
2NVIDIA® NVLink™ 連接器
3匯流排夾
4NVIDIA® NVLink™ 連接器
5液體冷卻入口
-
-

-
30XLLM 推論NVIDIA H100 Tensor Core GPU
-
4XLLM 訓練H100
-
25X能源效率H100
-
18X資料處理CPU
- LLM 推論和能源效率:TTL = 50 毫秒 (ms) 實時,FTL = 5 秒,32,768 輸入/1,024 輸出, NVIDIA HGX™ H100 透過 InfiniBand (IB) 擴展與 GB200 NVL72 比較,訓練 1.8T MOE 4096x HGX H100 擴展 透過 IB 與 456x GB200 NVL72 透過 IB 擴展比較。叢集大小:32,768
- 具有 Snappy / Deflate 壓縮的資料庫聯接和聚合工作負載,源自 TPC-H Q4 查詢。 x86、H100 單個 GPU 和來自 GB200 NLV72 的單個 GPU 與 Intel Xeon 的自定義查詢實現 8480+
- 預計效能如有變更,恕不另行通知
-
-
大規模的 AI 基礎架構
華碩透過利用強大的 NVIDIA GB200 NVL72,持續展示其在建構 AI 基礎架構方面的專業知識。 這個先進的系統安裝在具有多個運算節點的單個機架中,消耗約 120kW 的電力。 鑑於這種巨大的電力需求,資料中心營運商必須重新評估和升級現有的 拓撲和配置。最佳化工作應側重於透過增強的散熱、穩定的網路連接以及設施的整體架構完整性來確保效能穩定。隨著 AI 工作負載 變得越來越嚴苛,這些基礎架構的改進對於在保持運作穩定性的同時,實現效能和效率目標至關重要。
-
最大化效率,最小化熱量
液冷架構
華碩與合作夥伴合作,提供全面的機櫃級液冷解決方案。這些解決方案包括 CPU/GPU 冷板、冷卻分配單元和冷卻塔,所有這些都旨在最大限度地減少功耗並優化資料中心的電源使用效率 (PUE)。
-

液體到空氣解決方案
非常適合具有緊湊型設施的小型資料中心。
旨在滿足現有氣冷資料中心的需求,並輕鬆與當前基礎架構整合。
非常適合尋求立即實施和部署的企業。 -

液體到液體解決方案
非常適合具有高工作負載的大規模、廣泛的基礎架構。
提供長期的低 PUE,並隨著時間的推移保持能源效率。
降低 TCO 以實現最大價值和具有成本效益的營運。
-
-
極致 快速
NVIDIA GB200 NVL72 中的第五代 NVLink 技術
NVIDIA NVLink Switch 具有 144 個連接埠,交換容量為 14.4 TB/s,允許九個交換器與單個 NVLink 網域內 72 個 NVIDIA Blackwell GPU 中的每一個上的 NVLink 連接埠互連。
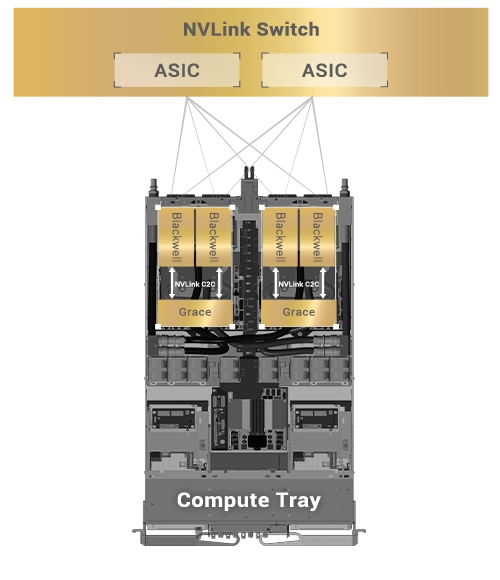
單個運算托盤中的 NVLink 連接,確保直接連接到所有 GPU
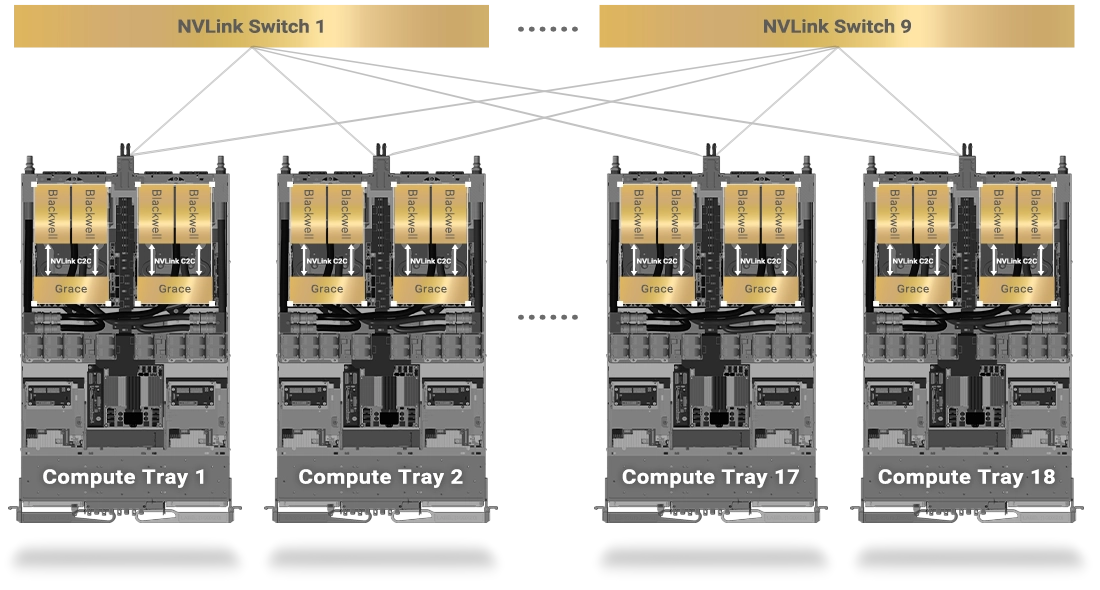
單個機架中的 NVLink 連接
-
華碩 Premiere Service Suite
透過從硬體到應用程式的全方位整合來改造資料中心
華碩透過提供從設計和建構到實施、驗證、測試和部署的全方位服務,重新定義了其基礎架構服務架構。這與雲端應用程式服務無縫整合,所有這些都透過客製化的、客戶特定的服務模型交付,以滿足不同的客戶 需求。
-

架構設計
-

大規模部署
-

配置測試
-

客製化
-

雲端服務
-

專案交付

-
-
加速您的上市 時間
華碩自有的軟體和控制器
NVIDIA NVLink Switch 具有 144 個連接埠,交換容量為 14.4 TB/s,允許九個交換器與單個 NVLink 網域內 72 個 NVIDIA Blackwell GPU 中的每一個上的 NVLink 連接埠互連。
-
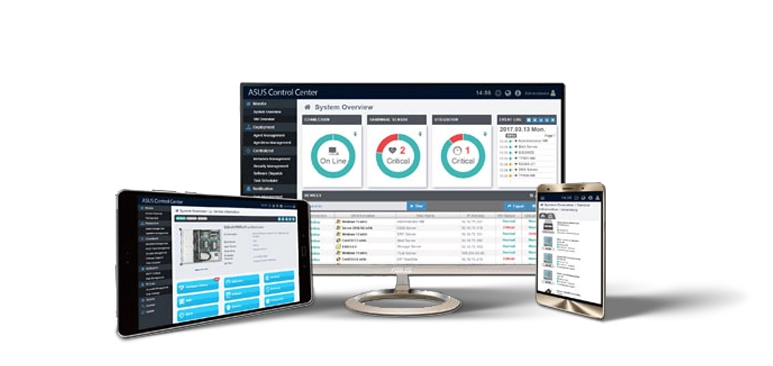
華碩控制中心 (ACC)
集中式 IT 管理軟體,用於監控和控制華碩伺服器
- Power Master – 針對資料中心的有效能源控制
- 輕鬆搜尋和控制您的裝置
- 輕鬆快速地增強資訊安全
-
華碩基礎架構部署中心 (AIDC)
單一管理控制台,可實現集中式遠端部署
- 自動化和系統化
- 集中式配置控制和管理
- 加速機架級基礎架構的部署
-
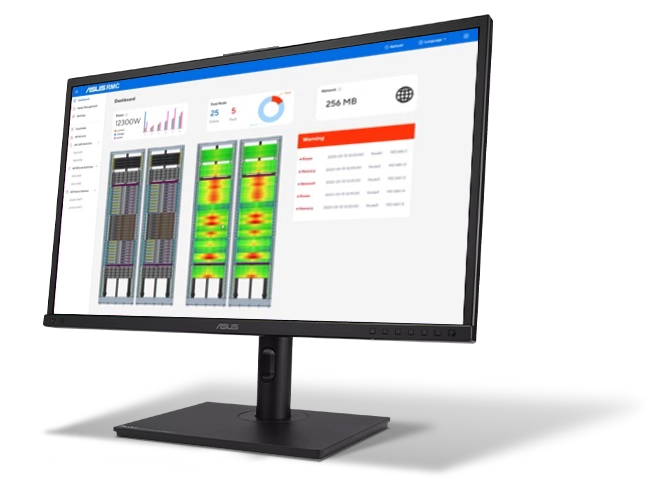
機架管理控制器 (RMC)
用於伺服器機架內遠端硬體管理的集中式控制器
- 故障排除、管理和維護
- 批次監控
-


